
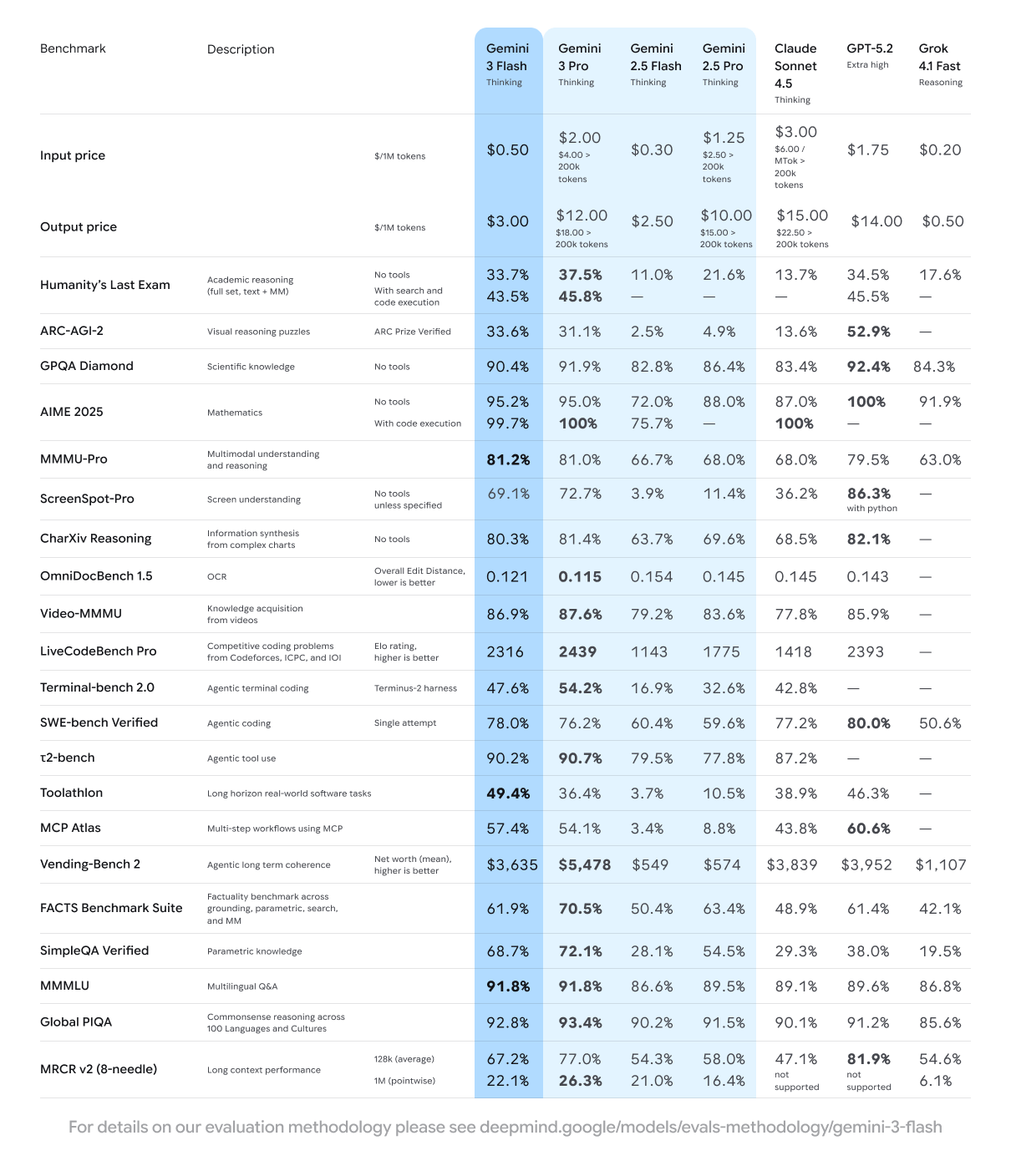
Google has just released Gemini 3 Flash, and it's obliterating the traditional AI trade-off that has frustrated developers and everyday users for years. You know the drill: pick a powerful model that takes forever to respond, or choose a speedy one that gives you shallow answers. Gemini 3 Flash tosses that compromise out the window.
The new model scores 90.4% on GPQA Diamond—a benchmark designed to stump PhD-level experts—while running three times faster than its predecessor, Gemini 2.5 Pro. Even more impressive, it costs less than a quarter of what Gemini 3 Pro charges, at just $0.50 per million input tokens.
Harvey, an AI company serving law firms, reported over 7% accuracy improvements on legal document analysis while maintaining Flash's characteristic low latency—the kind of performance gain that matters when you're extracting contract terms at scale.
What Makes This Different
Flash models have already processed trillions of tokens across hundreds of thousands of apps built by millions of developers, making them Google's workhorses. But Gemini 3 Flash brings something new: frontier performance on PhD-level reasoning benchmarks while using 30% fewer tokens on average than 2.5 Pro to complete everyday tasks.
The practical impact shows up immediately. Gaming platform Latitude, which previously needed expensive pro-level models like Sonnet 4.5, now delivers high-quality outputs at low costs using 3 Flash for their next-generation game engine. Meanwhile, Resemble AI discovered 4x faster multimodal analysis for deepfake detection compared to 2.5 Pro, enabling near-real-time forensic intelligence.
How to Access It Now
Gemini 3 Flash is rolling out globally starting today. You'll find it as the default model in the Gemini app (replacing 2.5 Flash), available at no cost for everyday users. In Google Search's AI Mode, it's now powering responses worldwide with real-time information and web links.
Developers can access it through Google AI Studio, the Gemini API, Vertex AI, and Google's new Antigravity coding platform. The model includes context caching (cutting costs by 90% for repeated prompts) and Batch API support (50% savings for asynchronous processing).